Explaining the overall use of the Python numpy.random package
The aim of this project was to explain the overall use of the Python numpy.random package and in particular the use of it’s simple random data functions, it’s permutations functions and it’s distributions functions. The final section explains the use of seeds in generating pseudorandom numbers.
This was the first project for the Programming for Data Analysis module at GMIT as part of the Higher Diploma in Computing and Data Analytics.
There were four distinct task to be carried out for this assignment.
An overview of each task is provided at the links below.
importlibrariesusingcommonaliasnamesimportnumpyasnpimportpandasaspdimportseabornassnsimportmatplotlib.pyplotaspltnp.set_printoptions(precision=4)# set floating point precision to 4np.set_printoptions(threshold=5)# summarise long arraysnp.set_printoptions(suppress=True)# to suppress small results
numpy.random is a sub-package of NumPy for working with random numbers and is somewhat similar to Python’s standard library random but instead works with numpy arrays. It can create arrays of random numbers from various statistical probability distributions and also randomly sample from arrays or lists. The numpy.random module is frequently used to fake or simulate data which is an important tool in data analysis, scientific research, machine learning and other areas. The simulated data can be analysed and used to test methods before applying to the real data. See more of task 1
numpy.random contains some simple random data functions for random sampling of both discrete and continuous data from the uniform, normal or standard normal probability distributions and for randomly sampling from a sequence or set of elements. It also has two permutations function for shuffling arrays. These functions all return either arrays of random values where the number of dimensions and the number of elements can be specified or scalar values. See more task 2
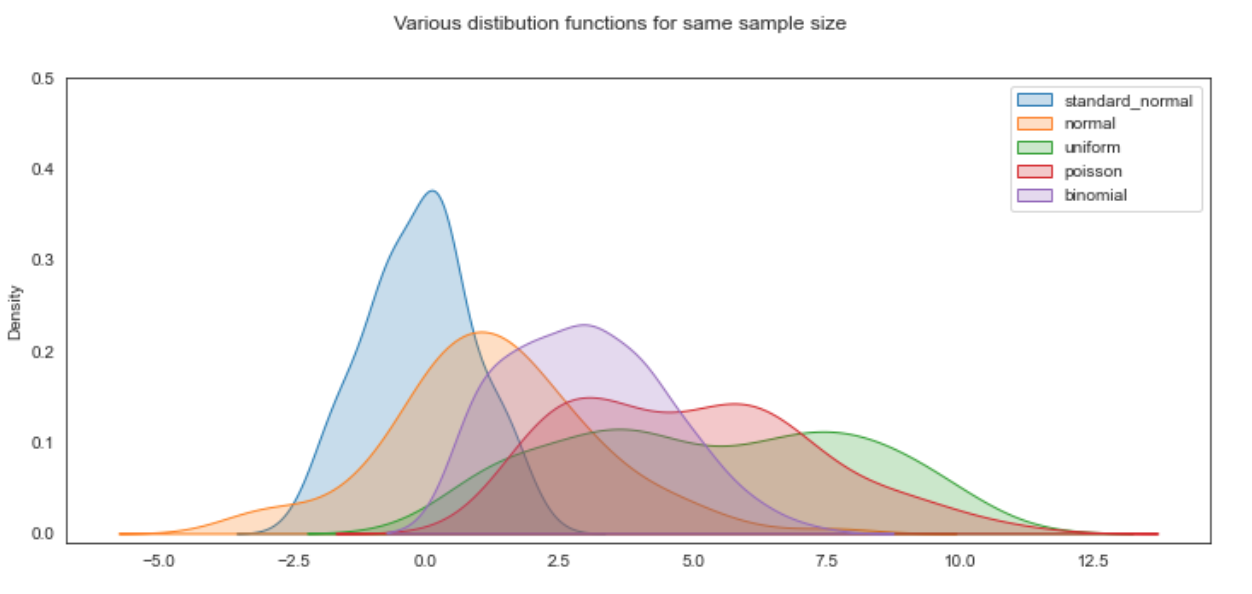
Samples of random numbers can be drawn from a variety of probability distributions.
Each of the numpy.random distribution functions generate different random numbers according to different probabilities over different intervals and can be used to simulate and understand data. There are specific applications and uses for each type of distribution. However the distributions can nearly all be related to each other or transformed into each other in some way or other. See more of task 3
Computer programs produce outputs based on inputs and according to a set of predetermined rules. Pseudorandom numbers are generated in a sequence according to some deterministic algorithm from an input called a seed which is a number that is used to initialise the pseudorandom number generator. The seed used is typically the time in milliseconds on the computer when the code was run and is used as the starting point of the process.
Pseudo random number generators can be seeded which makes them deterministic. To recreate the exact same sequence of random numbers, then you can just explicitly supply the seed as an input to the random number generator. This means that while the numbers generated look random they are not truly random but pseudorandom. These pseudorandom numbers contain no real randomness at all - randomness is just being imitated - but they can take the role of random numbers for certain applications.
See more of task 4
A rendered version of the full Jupyter notebook can be read here.
numpy.random is a sub-package of NumPy for working with random numbers and is somewhat similar to the Python standard library random but works with NumPy’s arrays. It can create arrays of random numbers from various statistical probability distributions and also randomly samples from arrays or lists.
NumPy’s random module is frequently used to fake or simulate data which is an important tool in data analysis, scientific research, machine learning and other areas. The simulated data can be analysed and used to test methods before applying to the real data.
Python’s standard library random already provides a number of tools for working with random numbers. However it only samples one value at a time while numpy.random can efficiently generate arrays of sample values from various probability distributions and also provides many more probability distributions to use. The numpy.random module is generally much much faster and more efficient than the stdlib random particularly when working with lots of samples, however the random module may be sufficient and more efficient for other simpler purposes.
As well as being able to generate random sequnces, NumPy’s random module also has functions for randomly sampling elements from an array or sequence of elements, numbers or otherwise.
Both of these random modules generate pseudorandom numbers rather than actual random numbers. Computer programs are deterministic because their operation is predictable and repeatable. They produce outputs based on inputs and according to a set of predetermined steps or rules so therefore it is not really possible for a computer to generate truly random numbers. These random modules implements pseudorandom numbers for various distributions that may appear random they are not truly so.
There are many computational and statistical methods that use random numbers and random sampling. Gaming and gambling applications involve randomness. Scientific and numerical disciplines use it for hypothesis testing. Statistics and probability involve the concept of randomness and uncertainty. Monte carlo simulation uses random numbers to simulate real world problems. Monte Carlo methods, or Monte Carlo experiments, are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results. The underlying concept is to use randomness to solve problems that might be deterministic in principle. Monte-carlo simulators are often used to assess the risk of a given trading strategy say with options or stocks. A monte carlo simulator can help one visualize most or all of the potential outcomes to have a much better idea regarding the risk of a decision.
The ability to generate sets of numbers with properties from a particular probability distribution is also very useful for simulating a dataset, maybe prior to the real dataset becoming available but also for demonstrating of and learning statistical and data analysis concepts.
Data Analytics and Machine learning projects frequently use random sampling on actual datasets for testing and evaluation analytical methods and algorithms. A set of samples of data are studied and then use to try and predict the properties of unknown data. In machine learning, a dataset can be split into training and test set where the dataset is shuffled and a classifier is built with a randomly selected subset of the dataset and the classifier is then tested on the remaining subset of the data. A train-test split is used for model selection and cross validation purposes
The machine learning algorithms in the scikit-learn package use numpy.random in the background. There is a random element to the train_test split as it uses numpy.random to randomly choose elements for the training array and the test array. Cross validation methods such as k-fold validation randomly split the original dataset into training and testing subset many times.